

Dans LODEX, les enrichissements sont par défaut en mode simple, et n’ont que peu de paramètres.
Une manière d’accéder à plus de paramètres est de passer en mode avancé.
On se trouve alors face à un script modifiable.
Ce script pouvant être un peu abscons, le but de cet article est d’expliquer quelles parties de ce script sont intéressantes à modifier, et pourquoi faire.
Créer un enrichissement simple
Pour créer un enrichissement, il faut avoir chargé un corpus (via l’administration de LODEX).
Nous supposerons que ce corpus dispose d’une colonne abstract contenant un résumé en anglais.
Ensuite, il faut se rendre dans le menu Données / Enrichissements :
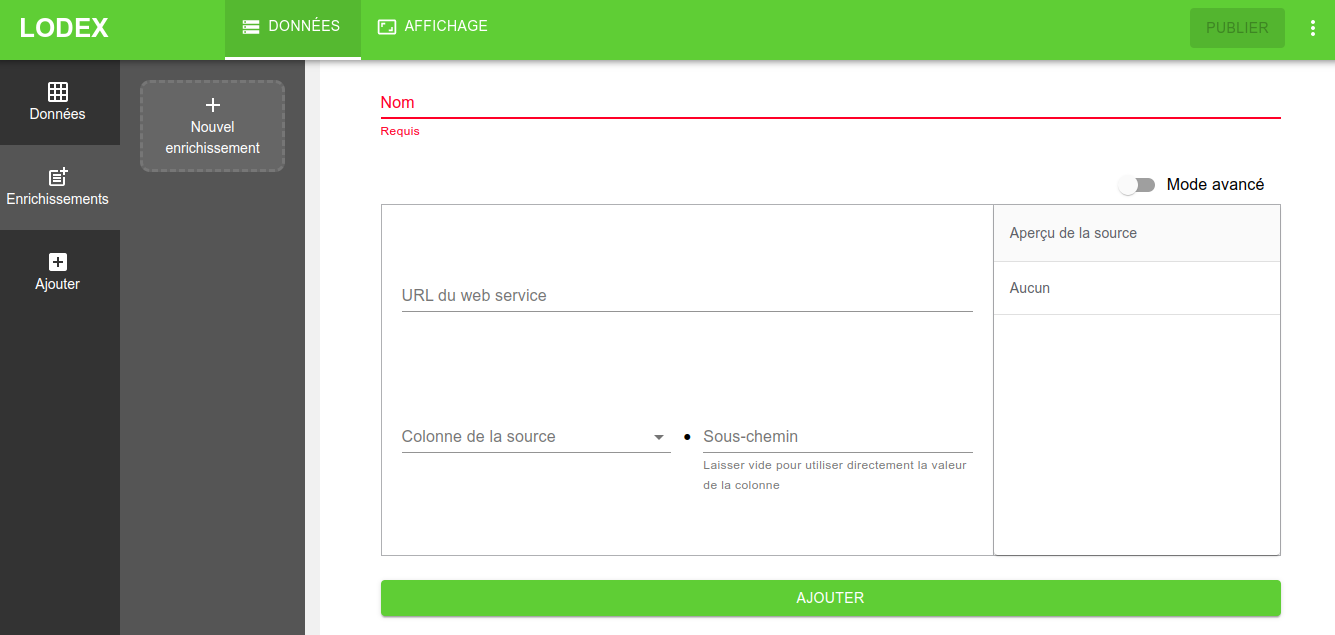
Prenons comme exemple d’enrichissement simple l’extraction de termes d’un texte avec l’algorithme Teeft.
Nommons l’enrichissement que nous créons teeft, ce sera le nom de la colonne correspondante.
Le service web à utiliser est décrit sur la page Extraction de termes d’un texte via Teeft d’Objectif TDM.
On y voit que l’URL du service web à utiliser est https://terms-extraction.services.inist.fr/v1/teeft/fr?nb=10.
Copions-la dans le champ ad hoc.
Ensuite, sélectionnons la colonne abstract puisque c’est celle que dont nous voulons extraire les termes pertinents.
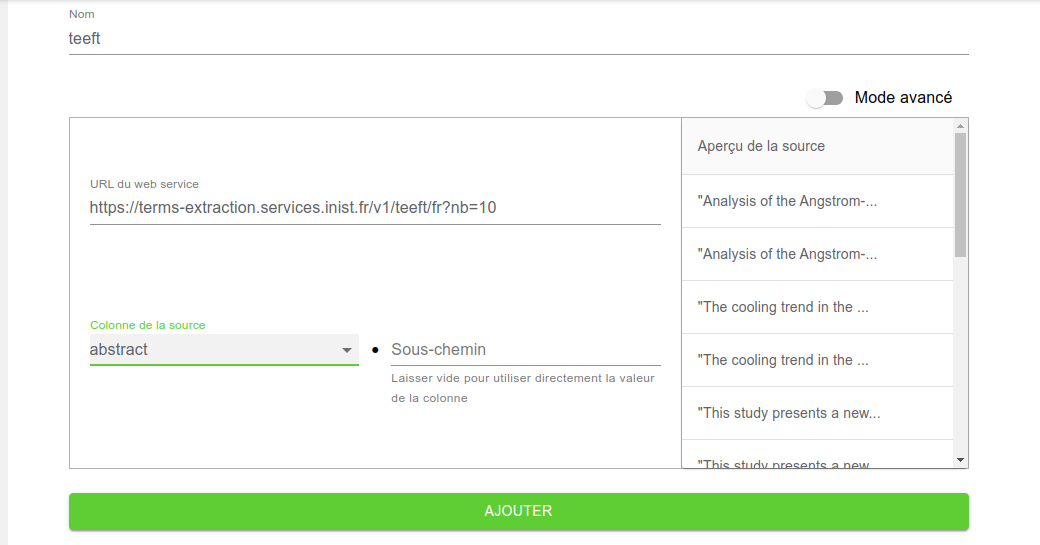
Il reste à cliquer sur Ajouter pour créer l’enrichissement, et permettre d’accéder au script correspondant à ces paramètres.
Une fois l’enrichissement ajouté, deux nouveaux boutons apparaissent: Lancer et Supprimer.
Visualiser le script correspondant
En actionnant le bouton Mode avancé, le formulaire est remplacé par un éditeur présentant le script généré à partir de ses paramètres.
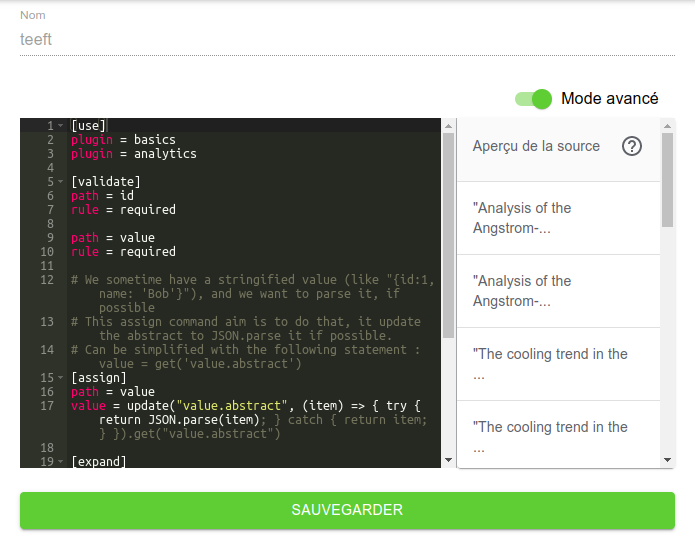
Dans notre cas, il contient :
[use]
plugin = basics
plugin = analytics
[validate]
path = id
rule = required
path = value
rule = required
# We sometimes have a stringified value (like "{id:1, name: 'Bob'}"), and we want to parse it, if possible
# This assign command's aim is to do that, it updates the abstract to JSON.parse it if possible.
# Can be simplified with the following statement : value = get("value.abstract")
[assign]
path = value
value = update("value.abstract", (item) => { try { return JSON.parse(item) } catch { return item } }).get("value.abstract")
[expand]
size = 10
path=value
# remove the two lines below to speed up enrichment
[expand/throttle]
bySecond = 5
[expand/URLConnect]
url = https://terms-extraction.services.inist.fr/v1/teeft/fr?nb=10
timeout = 5000
noerror = false
retries = 5
Analyse du script
Le script affiché est écrit dans un langage de traitement de flux de données appelé ezs.
Démystifions chaque partie de ce script (dont la syntaxe est la même que les fichiers .ini qui servent de fichiers de configuration à certains programmes).
D’habitude, les crochets encadrent le nom d’une partie de configuration.
Ici, ils marquent la présence d’une instruction ezs.
Détaillons chacune de ces instructions.
use
[use]
plugin = basics
plugin = analyticsL’instruction use déclare les plugins (ou modules) du langage ezs que le script va utiliser.
Les instructions sont réparties soit dans le cœur d’ezs (nommé @ezs/core), soit dans un de ses modules.
Ici par exemple, l’instruction URLConnect appartient au module @ezs/basics.
À moins que nous ajoutions des instructions non encore présentes dans le script, nous pouvons donc ignorer cette partie.
validate
[validate]
path = id
rule = required
path = value
rule = requiredL’instruction validate s’assure simplement que la structure des objets à traiter est la bonne.
Elle attend un objet JavaScript (JSON en anglais) avec au moins un champ id et un champ value.
{
"id": "...",
"value": "..."
}Ici encore, c’est LODEX qui s’assure d’envoyer des objets qui respectent cette structure.
Dans notre cas, le champ id contiendra un numéro d’ordre et le champ value tout le document en train de passer dans le flux (c’est-à-dire un objet contenant toutes les colonnes chargées).
Si d’aventure LODEX venait à ne pas respecter cette structure, une erreur s’afficherait lors du lancement de l’enrichissement.
Mais c’est très peu probable.
On peut donc aussi ignorer cette instruction.
assign
L’instruction assign ajoute un champ, ou bien modifie simplement un champ déjà existant de l’objet du flux qu’elle est en train de traiter.
# We sometimes have a stringified value (like "{id:1, name: 'Bob'}"), and we want to parse it, if possible
# This assign command's aim is to do that, it updates the abstract to JSON.parse it if possible.
# Can be simplified with the following statement : value = get('value.abstract')
[assign]
path = value
value = update("value.abstract", (item) => { try { return JSON.parse(item); } catch { return item; } }).get("value.abstract")Ici, le commentaire explique pourquoi la ligne avec le paramètre value est si longue, et que dans les cas les plus courants, on peut se contenter d’écrire cette instruction comme suit :
[assign]
path = value
value = get("value.abstract")Cette instruction va modifier le champ value (donc l’objet contenant toutes les colonnes) pour lui affecter uniquement sa colonne abstract.
On passera donc d’un objet du genre :
{
"id": "001",
"value": {
...
"abstract": "Le résumé en anglais",
...
}
}à un objet ressemblant à :
{
"id": "001",
"value": "Le résumé en anglais"
}ce qui, si vous y avez prêté attention, est le format d’entrée nécessaire au service web teeft.
Là aussi, LODEX a tout préparé pour nous, et en principe nous n’aurons rien à y toucher.
Évidemment, quand vous maîtriserez ezs, vous pourrez vous livrer à quelques facéties, comme concaténer le contenu de deux colonnes, ou bien appauvrir un texte (en lui enlevant ses caractères accentués, ou en le passant en minuscules, voire les deux).
Ne touchons donc pas à cette instruction.
expand
[expand]
size = 10
path=value
# remove the two lines below to speed up enrichment
[expand/throttle]
bySecond = 5
[expand/URLConnect]
url = https://terms-extraction.services.inist.fr/v1/teeft/fr?nb=10
timeout = 5000
noerror = false
retries = 5L’instruction expand est spéciale: elle fabrique un tableau de 10 éléments, tous les dix objets qu’elle reçoit, et exécute une sorte de sous-script.
Ici, le sous-script contient les instructions throttle et URLConnect.
Si nous négligeons throttle et considérons que URLConnect (dont nous verrons les paramètres plus bas) sert à appeler le service web, nous voyons que cette partie du script sert à envoyer plusieurs abstracts d’un coup au web service, réduisant ainsi le nombre de fois auquel on y fait appel.
Sachant que la rapidité du script dépend beaucoup du nombre d’appels au service web, il peut être salutaire de réduire ce nombre d’appels.
Cela peut se faire simplement en augmentant le paramètre size de expand :
[expand]
size = 100
path = valueEn le mettant à 100, nous faisons des paquets de 100 abstracts à envoyer au service web (divisant par 10 le nombre de requêtes).
Cependant, restons conscients que suivant la lourdeur du traitement à effectuer, augmenter size ne permettra pas forcément au service web d’être plus rapide.
En particulier, passer sa valeur à plus que 100 n’aura que rarement un effet positif.
Mais c’est un des paramètres qu’on peut se permettre de faire varier si l’enrichissement est trop long.
throttle
# remove the two lines below to speed up enrichment
[expand/throttle]
bySecond = 5throttle signifie littéralement « mettre au ralenti ».
Cette instruction sert à éviter l’engorgement du serveur du service web qu’on interroge.
En effet, il limite le nombre de requêtes à faire à 5 par seconde (ce qui, si on envoie 10 abstracts par requête, représente quand même 50 abstracts dont on extrait des termes par seconde).
Si on veut profiter de toute la puissance du serveur, on peut supprimer cette instruction.
Mais il faut rester conscient que cela signifie pratiquement s’accaparer les capacités du serveur.
Ça peut être acceptable si l’enrichissmenent est court, mais peut gêner d’autres utilisateurs s’il est long (il y a plus de chances que des enrichissements venant d’autres utilisateurs soient demandés pendant un enrichissement qui dure plus longtemps).
Pour être moins extrême, on peut aussi augmenter la limite de requêtes par seconde, en modifiant le paramètre bySecond, dans le but d’aller plus rapidement.
Gardons en tête que ce n’est pas le seul paramètre susceptible d’accélérer les traitements.
On lui préférera le paramètre size de l’instruction expand.
URLConnect
[expand/URLConnect]
url = https://terms-extraction.services.inist.fr/v1/teeft/fr?nb=10
timeout = 5000
noerror = false
retries = 5Le premier paramètre de URLConnect est évidemment l’url à utiliser.
Il y a ici un argument qu’on peut faire varier: nb. Il n’affecte pas les performances du service, mais seulement le nombre de termes à renvoyer.
Rappel: on ne peut pas vérifier que cette URL est la bonne simplement en la collant dans le navigateur. Techniquement, c’est la méthode
GETqui serait utilisée, alors que le service attend exclusivement une méthodePOSTassociée à l’URL.
retries représente le nombre d’essais que LODEX fera si l’appel au service échoue avant d’abandonner.
Mieux vaut ne pas l’augmenter, car il ne sert déjà que dans des cas extrêmes.
D’ailleurs, il peut expliquer des temps d’interrogation longs (au cas où l’URL ne serait pas bonne, par exemple).
De même, modifier noerror serait contre-productif: la seule autre valeur possible est true, et elle signifie qu’aucune erreur n’est signalée.
timeout en revanche, peut s’avérer utile.
Il arrive que certains services web nécessitant des calculs relativement lourds mettent plus que 5 secondes à répondre.
C’est un des cas où aucune erreur n’arrive à LODEX, car il ignorera toute réponse arrivant après le délai imparti.
C’est timeout qui fixe ce délai, dans ce script à 5000 millisecondes.
L’onglet données affichant les colonnes enrichies affichera undefined lorsque le timeout est dépassé.
C’est alors un fort indice qu’il faut augmenter la valeur de timeout.
Il pourrait arriver qu’un service prenne plus d’une minute pour un calcul (dépendant de la complexité du calcul, de la charge du serveur, …), n’hésitez donc pas à doubler la valeur de timeout quand vous obtenez des valeurs undefined dans la colonne enrichie correspondant au nom de l’enrichissement.
Lancement du script
Avant de lancer l’opération d’enrichissement, il ne faut pas oublier de cliquer sur SAUVEGARDER pour prendre en compte les modifications éventuelles du script.
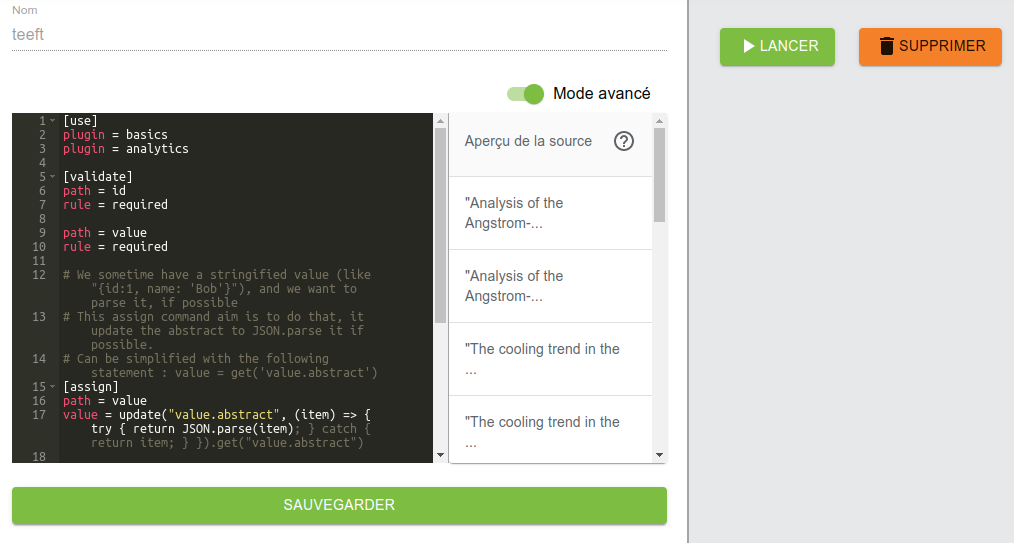 Cliquer sur
Cliquer sur LANCER exécute le script, sur toutes les données chargées.
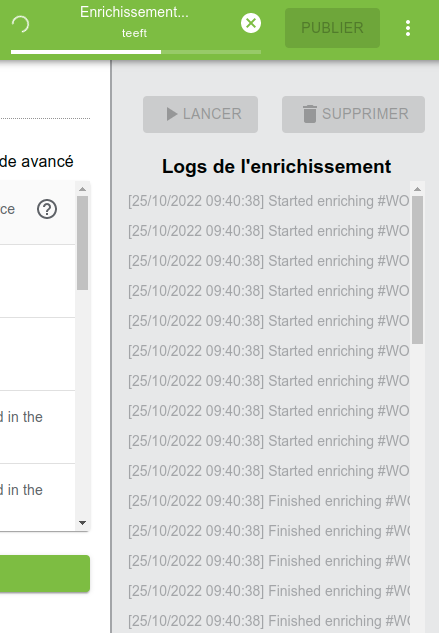 On peut ensuite aller voir le résultat en cliquant sur
On peut ensuite aller voir le résultat en cliquant sur Données.
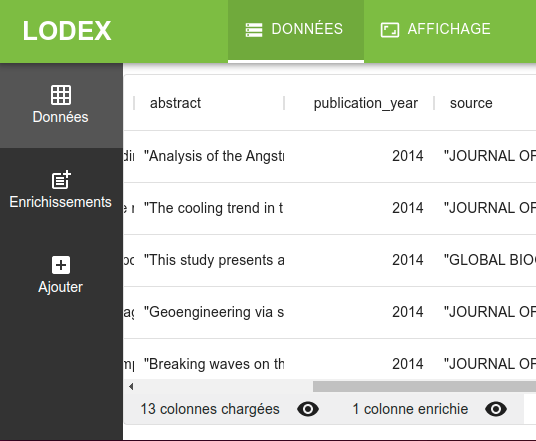 En cliquant sur
En cliquant sur colonnes chargées, on cache les colonnes correspondant aux données chargées initialement (sauf la colonne uri, qui est l’identifiant de chaque ligne).
On accède ainsi plus facilement aux colonnes enrichies, qui sont à droite des colonnes chargées.
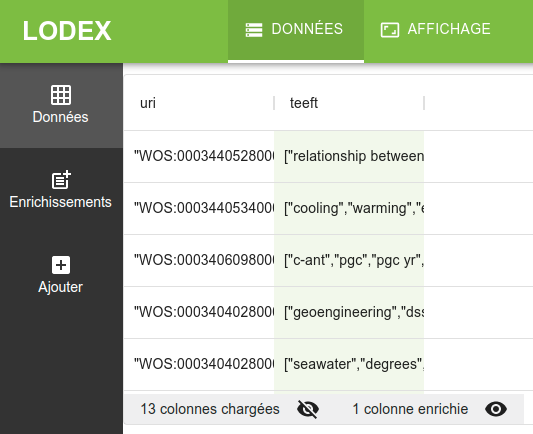 C’est à cet endroit qu’on peut repérer les valeurs
C’est à cet endroit qu’on peut repérer les valeurs undefined, pour savoir s’il faut augmenter le timeout de URLConnect, et relancer l’enrichissement (sans oublier de sauvegarder avant).
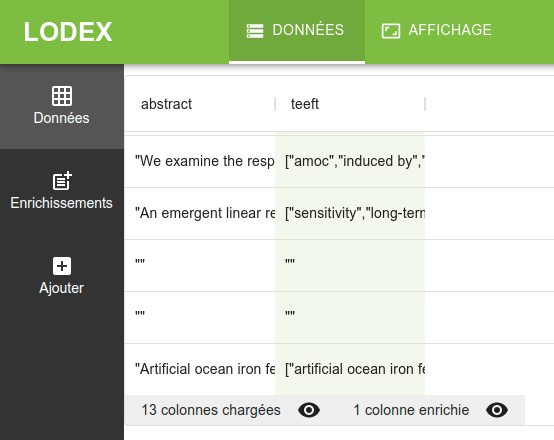
Remarque: il peut arriver que le service renvoie une réponse vide, c’est différent d’une valeur undefined, où aucune valeur n’a été retournée.
Ci-dessous, on voit des documents sans abstract, et dont le service n’a logiquement pas pu extraire de termes.
 Conclusion
Conclusion
Nous venons de voir l’utilisation d’un service web dont l’usage est simple (teeft, qui traite une chaîne de caractères).
Pour des besoins nécessitant un service web prenant en entrée une structure JSON plus détaillée, voir l’article Enrichissement RNSR dans LODEX.