

Au cours du projet VisaTM, nous avions produit une liste de trois cents outils spécialisés dans le traitement automatique du langage et la fouille de textes. L’idée générale de ce document était de disposer d’un premier panorama des applications disponibles. La description de chaque outil contenait les informations suivantes : présentation générale ; tâche(s) réalisée(s) ; licence ; pays de conception ; présence ou non dans la plateforme de fouille de textes Openminted (OMTD) ; site web de l’outil.
Nous avons décidé d’aller plus loin : transformer cette liste en ontologie computationnelle. L’objectif est, bien sûr, de proposer une représentation enrichie, formelle, explicite et manipulable par une machine de ces outils. À terme, nous souhaitons intégrer cette modélisation au sein d’une base de données d’applications spécialisées en fouille de textes. Nous espérons ainsi pouvoir aider les communautés scientifiques à découvrir les outils logiciels les plus adaptés pour leurs travaux de recherche. Nous présentons ici les prémices de ce travail, fruit d’une collaboration entre les équipes RichTEX (service Text and Data Mining) et Ingénierie terminologique de l’Inist-CNRS.
Pour construire OntoTM (Ontology of Text Mining), nous avons, dans un premier temps, transformé la liste d’outils en fichier OWL (Web Ontology Language). Le langage OWL permet de représenter les connaissances dans les ontologies informatiques. Dans un deuxième temps, et conformément aux pratiques recommandées en matière d’ingénierie ontologique, nous avons sélectionné un ensemble de classes et de propriétés provenant d’ontologies existantes pour nous aider à modéliser le domaine. L’idée, évidemment, était de ne pas réinventer la roue si des éléments de modélisation existaient déjà par ailleurs. Les ontologies externes suivantes ont été retenues :
- Basic Formal Ontology (BFO ; Arp et al., 2015) comme ontologie de haut niveau (dite aussi ontologie fondationnelle), cadre général, abstrait, permettant de classer les entités dans les grandes catégories de la réalité ;
- Information Artifact Ontology (IAO ; https://github.com/information-artifact-ontology/IAO/) comme ontologie noyau, intermédiaire, pour la modélisation des entités d’information ;
- Software Ontology (SWO ; Malone et al., 2014), pour la modélisation des logiciels ;
- Ontologie OMTD-Share (https://openminted.github.io/releases/omtd-share-ontology/1.0.0/) pour la modélisation des tâches de traitement automatique du langage et de fouille de textes, développée dans le cadre du projet européen Openminted.
La liste d’outils OWL et les ontologies externes ont ensuite été fusionnées au sein d’une même ontologie : OntoTM est née. Quand cela s’est avéré nécessaire, de nouvelles classes et propriétés ont été introduites dans l’ontologie. La figure 1, ci-dessous, présente la hiérarchie des classes dans OntoTM. Un logiciel réalisant des tâches de fouille de textes est considéré comme une sous-classe de la classe software application (IAO). La figure 2 détaille, sous forme graphique, les relations de domaine entre les principales classes.
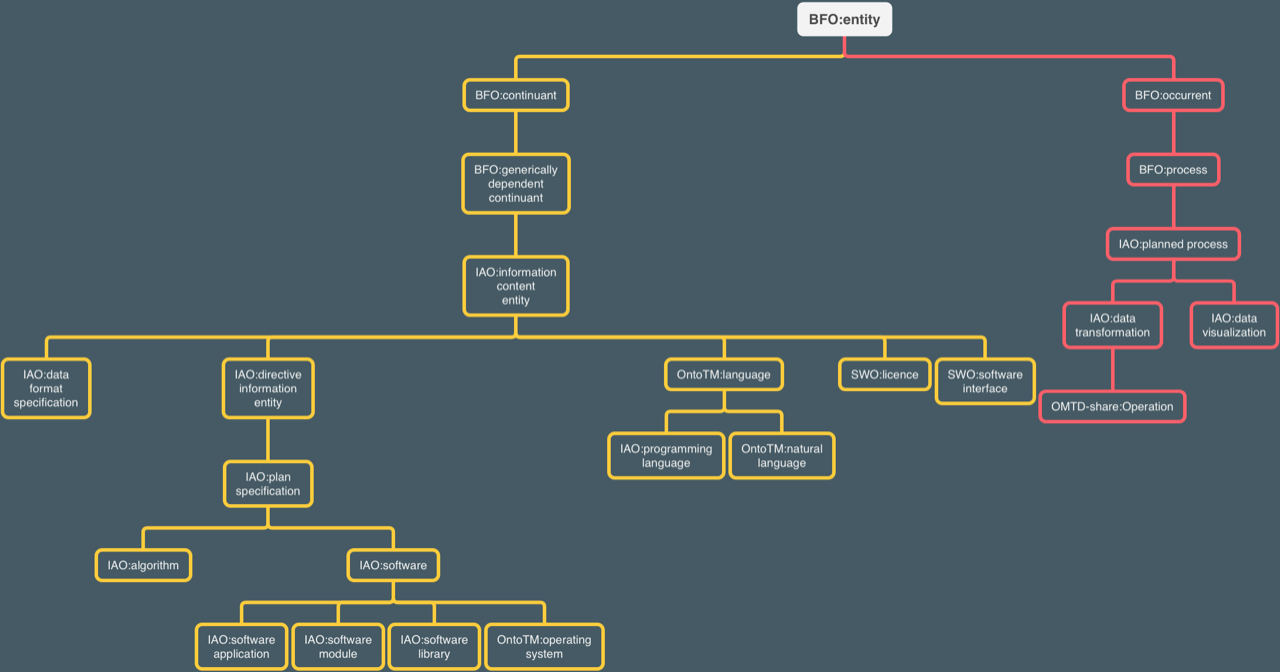 Figure 1 : Hiérarchie des classes principales dans OntoTM
Figure 1 : Hiérarchie des classes principales dans OntoTM
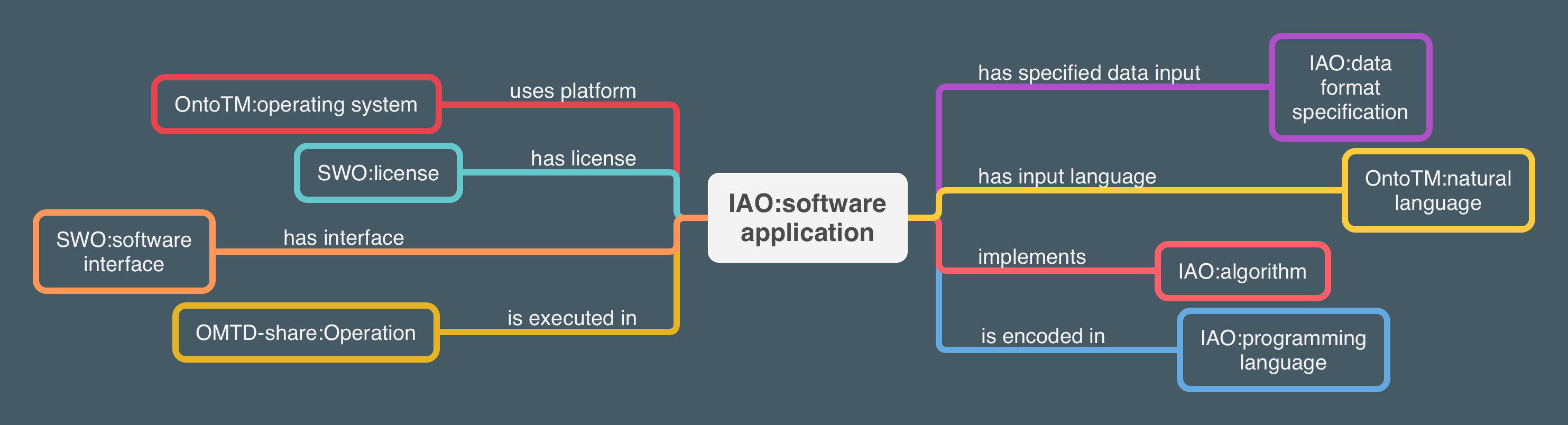
Figure 2. Relations de domaine entres classes dans OntoTM (cliquer sur l’image pour agrandir)
D’un point de vue pratique, le travail sur l’ontologie s’effectue désormais dans Webprotégé, version collaborative de l’éditeur d’ontologies Protégé, dont une instance a été installée à l’Inist-CNRS. Les premières descriptions formelles d’outils de fouille de textes ont débuté au sein d’OntoTM. La figure 3 est une capture d’écran de Webprotégé illustrant un essai de modélisation d’une application (Unitex).
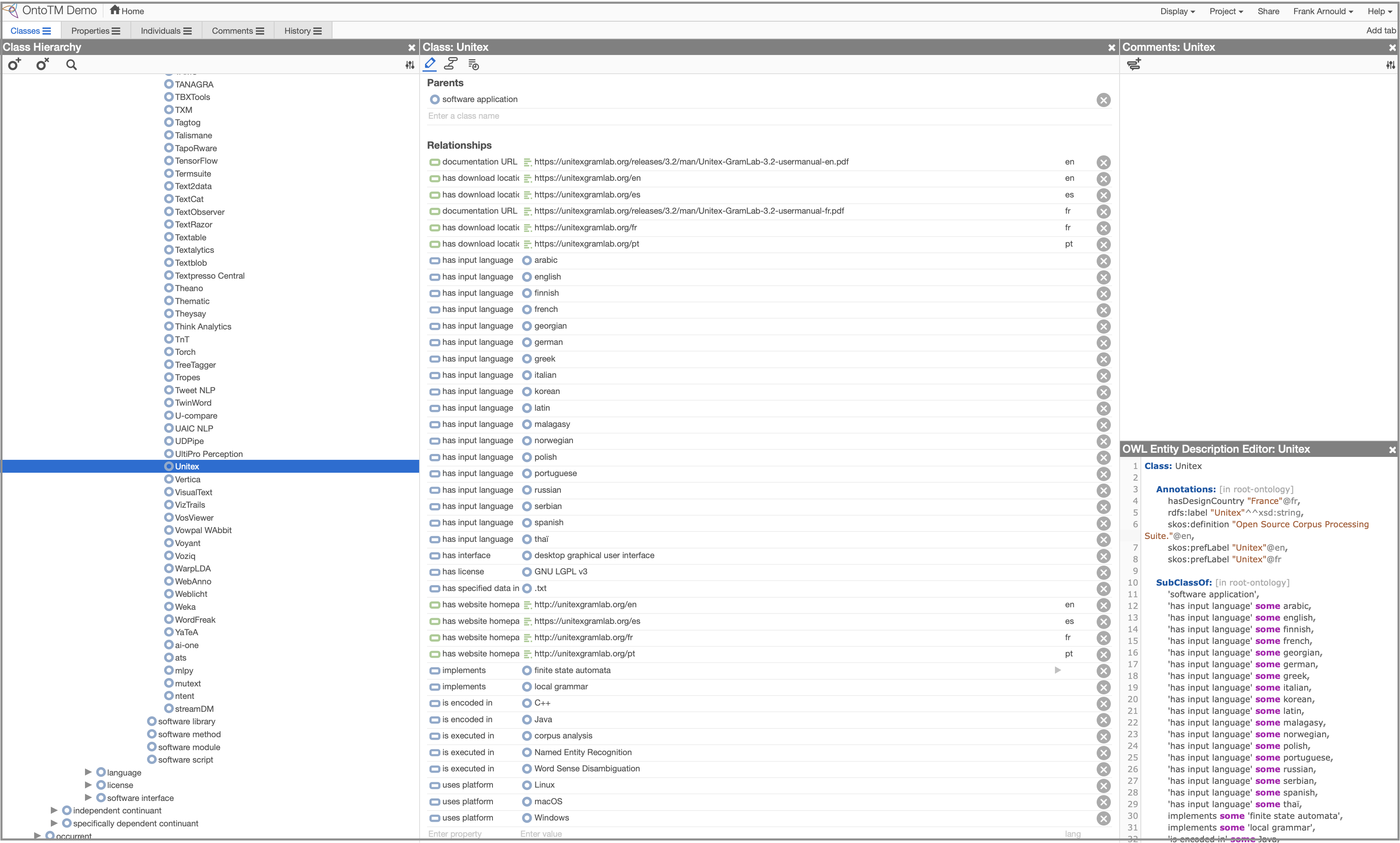
Figure 3. Test de modélisation de l’application Unitex dans OntoTM (cliquer sur l’image pour agrandir)
Le graphe complet de la modélisation d’Unitex est disponible en téléchargement :
Télécharger le graphe complet de la modélisation de l’outil Unitex
Les évolutions ultérieures d’OntoTM porteront sur une modélisation avancée des algorithmes implémentés dans les logiciels pour la fouille de textes, ainsi que sur la traduction en français des classes et propriétés présentes dans l’ontologie.
Références citées :
Arp, R., Smith, B., & Spear, A. D. (2015). Building Ontologies with Basic Formal Ontology. MIT Press.
Malone, J., Brown, A., Lister, A. L., Ison, J., Hull, D., Parkinson, H., & Stevens, R. (2014). The Software Ontology (SWO): A resource for reproducibility in biomedical data analysis, curation and digital preservation. Journal of Biomedical Semantics, 5(1), 25. https://doi.org/10.1186/2041-1480-5-25
Fabienne Kettani (Équipe Text et Data Mining, Inist-CNRS)
Frank Arnould (Équipe Ingénierie terminologique, Inist-CNRS)